Setting the scene…
Our team owns a collection of APIs which are responsible for managing restaurant information – data like their name, contact details, whether they’re currently open, etc. The clients of these APIs are mostly internal to JUST EAT. We’d recently seen that one of our write operations was behaving erratically when called in high load scenarios; causing high CPU usage on the EC2 instance hosting it, unacceptably long response times and generally being a bad citizen in our AWS ecosystem. A knock-on effect was other requests being received by the same instance were being queued with response times being negatively impacted. The operation looked like this:
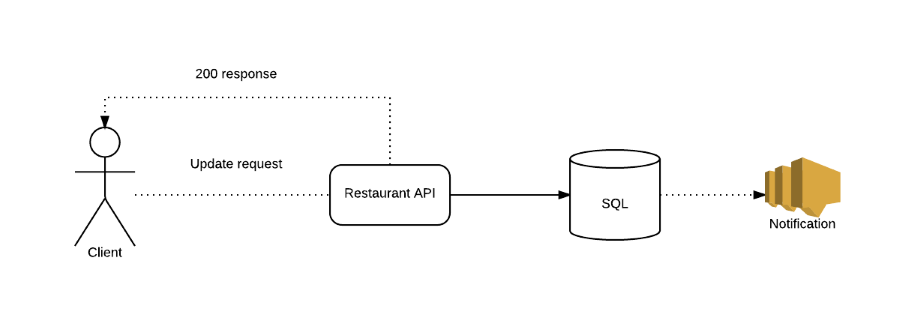
From profiling, it was obvious that this was a database-constrained task, so we first had a look at optimising the underlying SQL. Some simple changes allowed us to reduce the workload here; batching multiple updates into a single ‘UPDATE WHERE IN’, for example. This bought us a little bit of headroom, but didn’t fix the underlying problem, which is that the operation is SQL-heavy and can receive large amounts of traffic in a very short time under load.
On top of this, we had a new requirement to send an SMS notification as part of the workflow (hey, Twilio!). No matter how much we tuned the SQL/data side of things, there was no way to add that into the mix and still keep the response times of the operation in the handfuls-of-milliseconds that we like. Ultimately, it was clear that this current state of things wasn’t going to meet our needs going forward. What to do with a troublesome, long-running request like this?
Our solution
A notable aspect of this particular API operation is that it doesn’t guarantee that the work is completed immediately; the consumers of the operation are happy that it completes within ‘a few seconds’. This gave us flexibility to process the work asynchronously, away from the API and to notify the consumer of our progress, but how? We decided to create a new component that would be solely responsible for processing these long-running tasks, a Worker. The API could outsource the task to the Worker, freeing it up to service other requests.
We’re big fans of messaging and event architectures here at JUST EAT, so this sounded like a job for a lightweight command/message bus and, luckily, that’s exactly what we have in the form for our own open source solution JustSaying. Using JustSaying, the API publishes a command which describes the task for consumption by the Worker. We’ve made some changes to JustSaying so that it can publish this command directly to Amazon SQS with the Worker subscribing directly to that same queue. So, here’s what our API looks like now:
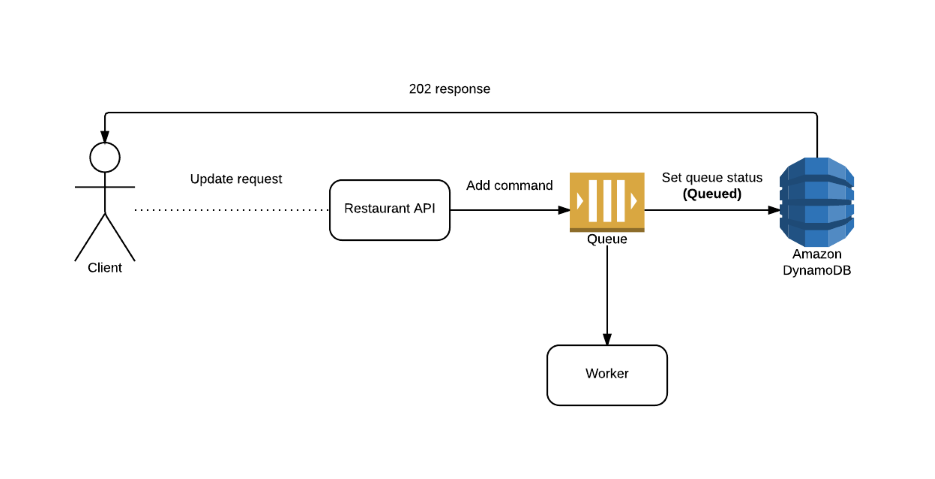
As you can see the API itself no longer does any processing. Instead, it has two simple (and fast-running) calls:
- Add a command to a queue.
- Add an item to an Amazon DynamoDB table to record the state of that command (initially ‘Queued’).
Thanks to JustSaying, publishing the command is as simple as:
var command = new UpdateRestaurantStatusCommand
{
...
}
commandBus.Publish(command);
The response (202 – Accepted) includes an ID and a resource URL for tracking the task state (‘Queued’, ‘Succeeded’, ‘Failed’, etc), using that DynamoDB table. At the other end of the queue, we have our new Worker component, responsible for processing those commands. We’ve implemented this as a Windows service hosted on an Amazon EC2 instance. Subscribing to the command, thanks to JustSaying, is as simple as:
commandBus
.WithSqsPointToPointSubscriber()
.IntoQueue("UpdateRestaurantStatusCommand")
.ConfigureSubscriptionWith(c =>
{
...
})
.WithMessageHandler(_updateRestaurantStatusCommandHandler)
.StartListening();
And here’s what the Worker looks like internally:

This may look slightly more complex than our original all-in-one API solution, but actually offers a host of additional benefits.
- The queue stores the commands until the Worker is free to process them; if the Service stops working no work is lost.
- We have automatic retries thanks to JustSaying.
- Unprocessed commands are added to a Dead Letter Queue (thanks again, JustSaying).
- We can scale the Service independent of the API.
- It now doesn’t matter how long the work itself takes as the consumer of the API gets a sub 20ms response.
- We can add extra functionality to the operation without impacting the API.
Show Me the Graphs
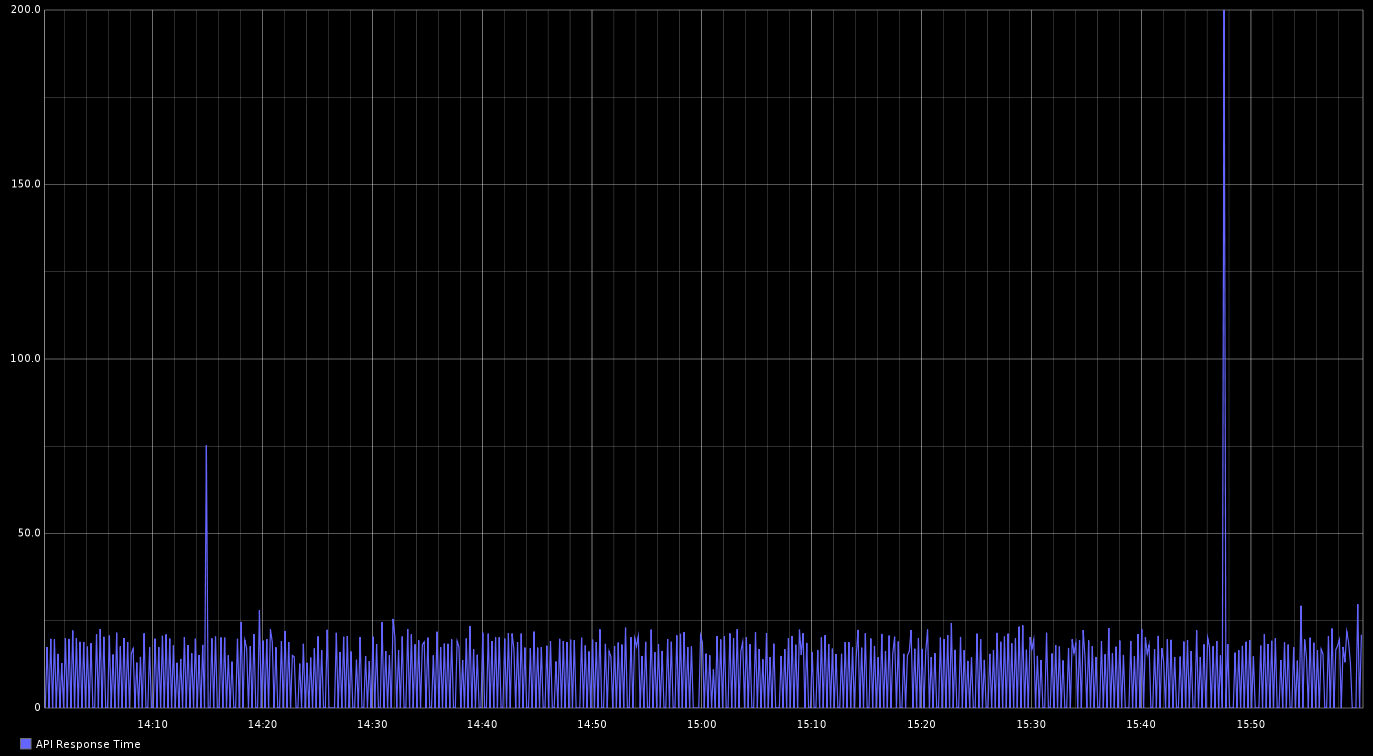
Being heavy users of monitoring at JUST EAT, we had plenty of historical data showing how the previous architecture was behaving under load, so we next ran some performance testing in one of our QA environments to see how the new system was behaving. We used JMeter for this, keeping an eye on our graphs. Immediately, we saw a dramatic decrease in the API response time, greater consistency in response times and a huge reduction in CPU load when sending very large numbers of requests. You can see below how consistently the API was now responding (the spikes you can see were due to DynamoDB calls taking longer than usual).
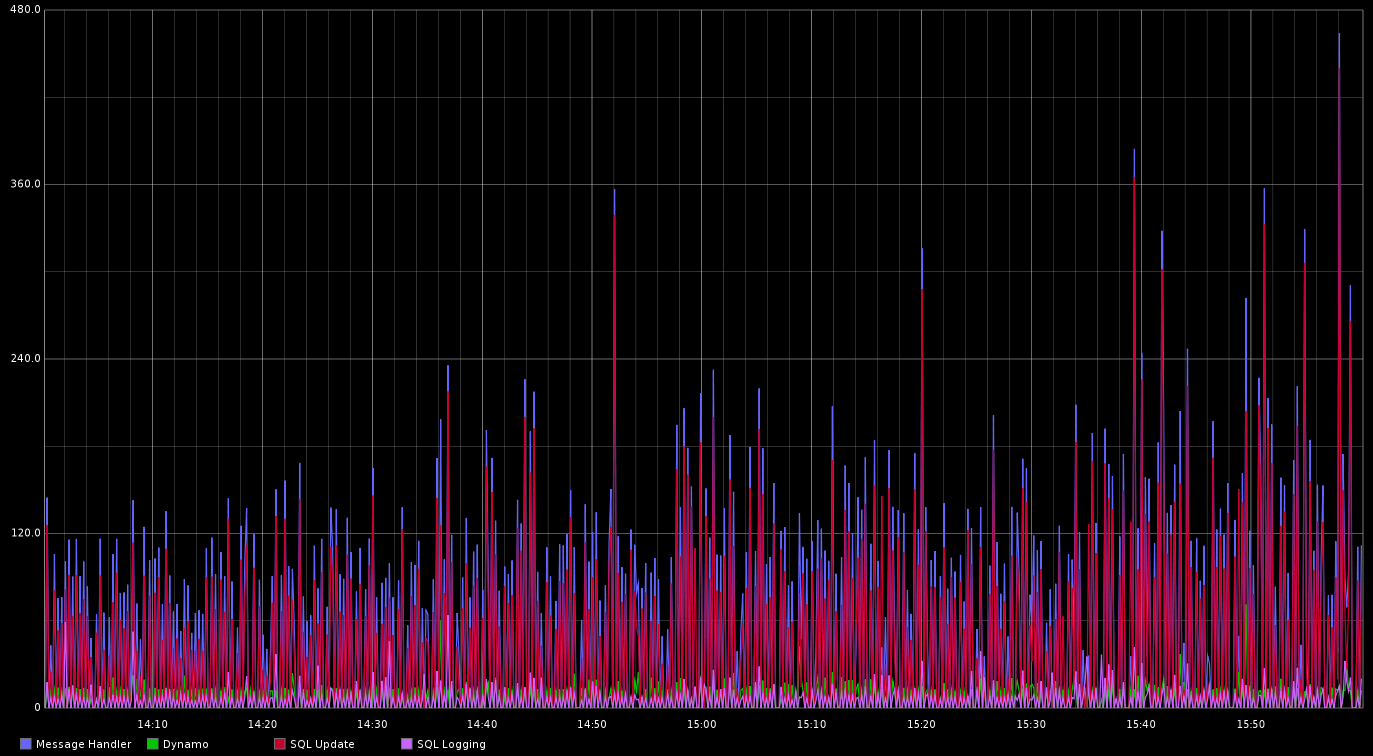
For the Worker itself, we added monitoring hooks to give us some insight into how the service was behaving. You can see in the next graph how the components of the Worker are running as part of the overall ‘handle a command’ operation. As we suspected, most clock time is still being spent in that same section of SQL as before – we’ve moved this from the API to the Worker but it’s still ultimately running the same piece of SQL.
With this benchmarking completed, it was clear that the new architecture was a significant improvement, so we felt eager to deploy to production!
Deployment
We validated the new the system in production by deploying a new instance of the Worker and a single instance of the new version of the API, allowing us to compare the two systems side-by-side under identical load. Comparing the response times from the original API call (old average) to the new one (new average), the response times for the API call are now around 20ms and no longer as erratic, just as we’d seen in our testing. Again, we do see an occasional spike as a result of the DynamoDB call, but increasing the write capacity will hopefully fix this.
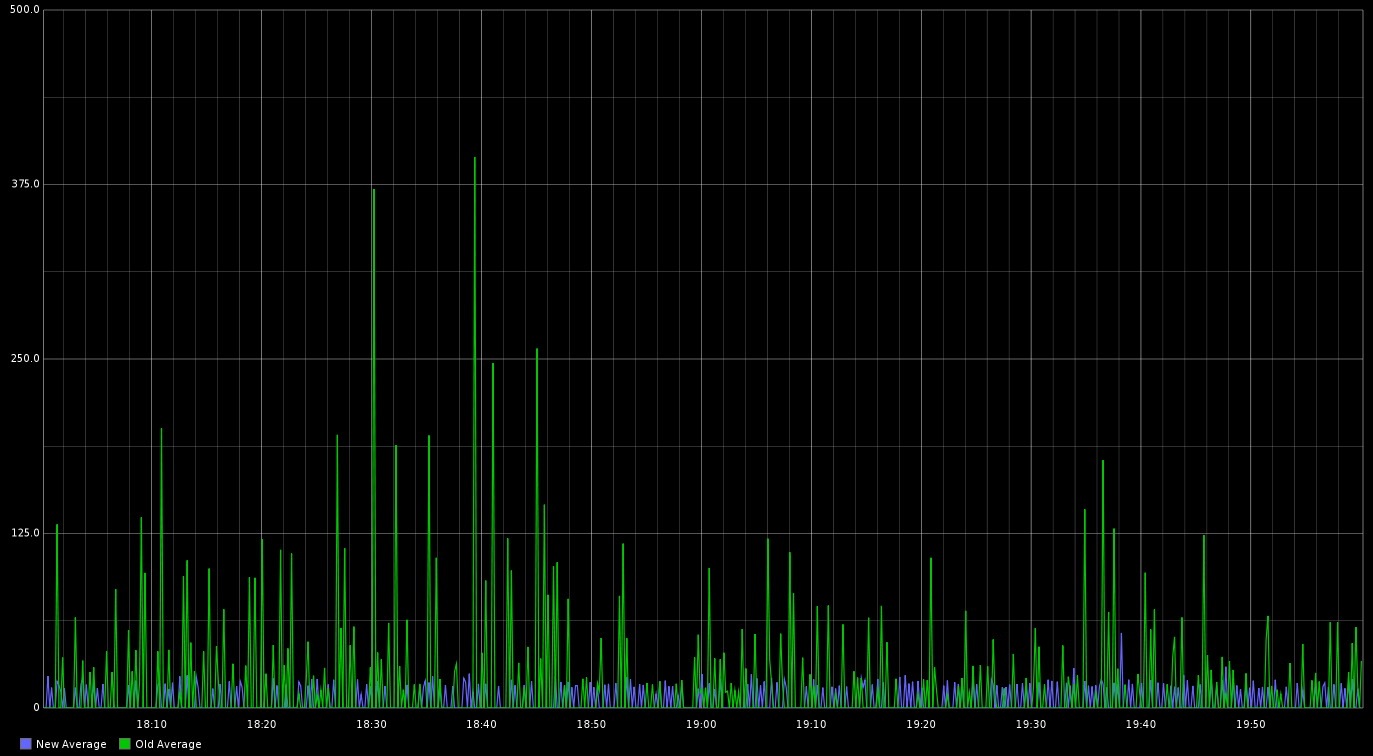
Similarly, the new Worker also behaves just as we expected from our testing. Success!
Operations
Since we believe in DevOps here, we know that to support our systems in production, we need comprehensive monitoring and alerting in place. Interestingly, what we found was that the monitoring that we’d set up as part of the performance testing we went through before deploying was pretty much exactly what we needed to monitor the health of the live system. How cool is that? This is why we love DevOps: because it means writing solid code with great instrumentation and monitoring up-front, reducing the chances of incidents in production (and being paged/woken up). In addition to the alerts around the response times of the API and the Worker, we have ones for the length of the command queue and the CPU utilisation of the Worker.
Conclusion
We have managed to decrease the response time for the operation and removed the bottleneck that this operation sometimes caused in IIS. We have moved the long running process to a service hosted on a different set of EC2 instances, which gives us greater control over scalability. By throttling how many messages each instance can process the queue gives us predictable performance, we can lower this amount if our instances are being strained (quicker than scaling more instances) or increase if we have a large backlog of commands we need to process. This approach will not work for all scenarios, such as when an API response has to return something in real time, but for cases where the consumer doesn’t need an immediate response there are plenty of benefits to moving the processing to an external service.