Replacing a legacy component with a new component in a production environment without downtime can be difficult. Within this post I will describe how we did just that! By running, in production, both components side by side, verifying that our new implementation would handle both load and business logic before slowly switching traffic from the old to the new component.
In part 1, I described the thought process and high level results that came from the work we did in replacing rather than refactoring existing APIs. In this part, we will delve deeper into the implementation of our new Search Architecture at Just Eat and the tools and techniques we used to achieve this without any down time.
Identifying the correct boundaries
Before we started work, we need to make sure that have had outlined the correct boundary for our components. We had a component which was doing too many things and had multiple responsibilities.
To start building something new we needed to understand these responsibilities clearly and define the purpose of the new API.
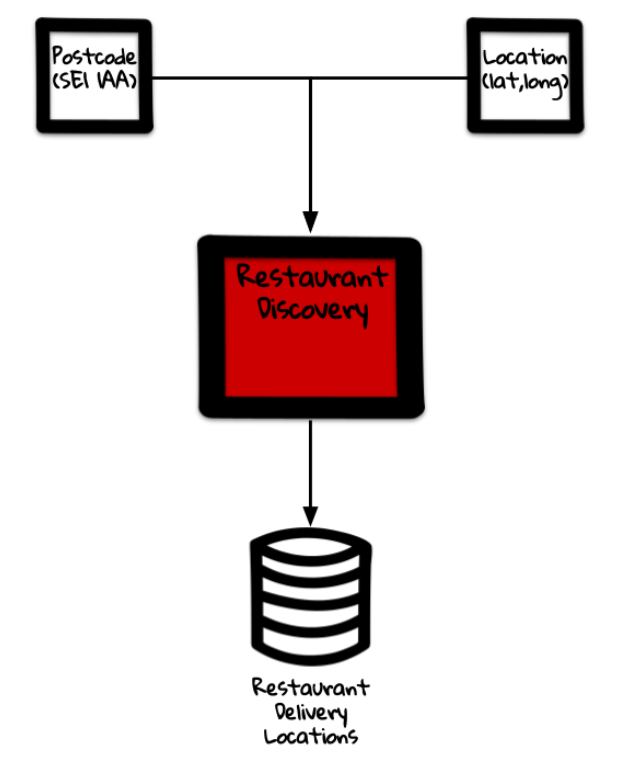
Restaurant Discovery
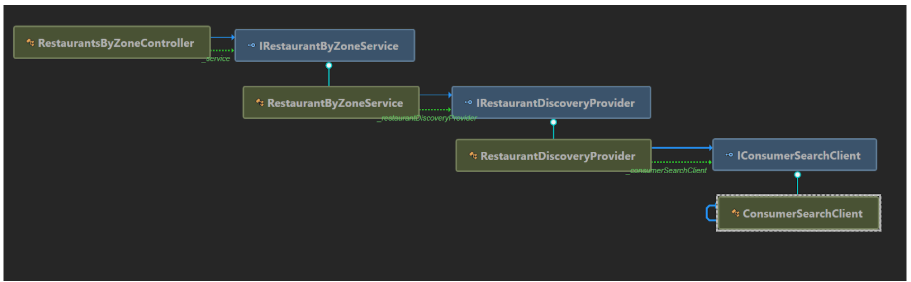
So, we already had implemented an orchestration layer within our domain, pulling sources of data together and aggregating these to expose externally. What we had yet to break out was the core functionality required to support searching for restaurants — Restaurant Discovery.
This would focus mainly on receiving the input of a location, for example a postcode or geospatial information (latitude/longitude), and return a list of restaurants which were available in those locations.
This was functionality that was already supported by our legacy component but was hard to decouple. It would be high risk to create a whole new component and then switch over all traffic to this.
If something went wrong this would cause massive problems for us and would likely have multiple components that would need to be rolled back and fixed in a production environment.
So, we worked out the following plan which we will go through step by step.
- MVP and Deploy Darkly
- Test, Test, Test
- Dual Call and Circuit Break
- Compare and Switch
- Deprecate!
MVP and Deploy Darkly
So, we took the minimal viable product (MVP) and the feature set that we thought would be required to support our new component. All the knowledge we had gathered within the team about our domain, we had a pretty good picture of what we needed to implement to get something to work. Over a period of 3 days, as part of a hackathon, we implemented the new component.
This was not a lift and shift. The legacy code we had, did everything we needed to. But it was such a tangled web that it was difficult to see through it to dissect just the pieces we needed.
In fact, our scope was so small that we knew it would be quicker just to rewrite from scratch. By doing this we also got the benefit of being able to jump to the latest and greatest frameworks, notably .net core, and take advantage of the benefits we got with this without having to worry about backward compatibility.
One piece of technical debt we did take on at this stage, was to connect to the same data store as the legacy component. We were not at this point going to change the schema as it did still fit quite nicely and the performance of this data store was not an issue. There were some aspects which were not going to be related to what we needed, but those could be tidied up later.
Although this meant that we technically broke a rule of microservices in sharing a data store (the horror!), it was a pragmatic approach that meant we were able to move a lot quicker and focus on solving one problem at a time.
Once we had this MVP, we were able to deploy darkly into our production environment. Not hooked up to anything and not receiving any live traffic (yet). With this we were able to quickly iterate and begin testing without impacting other production components.
Test, Test, Test
We had our component in production. Let’s start using it then, right? Hold your horses for a second there cowboy! We are talking about a critical code path that would have a massive impact on the site if something went wrong. We need to test it first.
Yes we had unit tests. Yes we had integration tests. We could prove that functionality was roughly the same. But we had yet to test to see whether this component was going to handle the load we would expect at peak time and would actually end up performing better than what we currently had.
From a business perspective, we needed to prove what these changes were going to improve customer conversion rate, reduce costs and reduce coupling. We knew this would reduce coupling of domains but, on its own, with other competing work, would be unlikely to get the approval for this to progress fully.
We needed to fully load test to give us an initial indication that we would see other benefits. What we did was to run a copy of current peak load traffic through the new component. By doing so, we were able to get a picture of how it would perform. The results were very promising. We managed to achieve the full production load traffic on 10% of the hardware of the previous component.
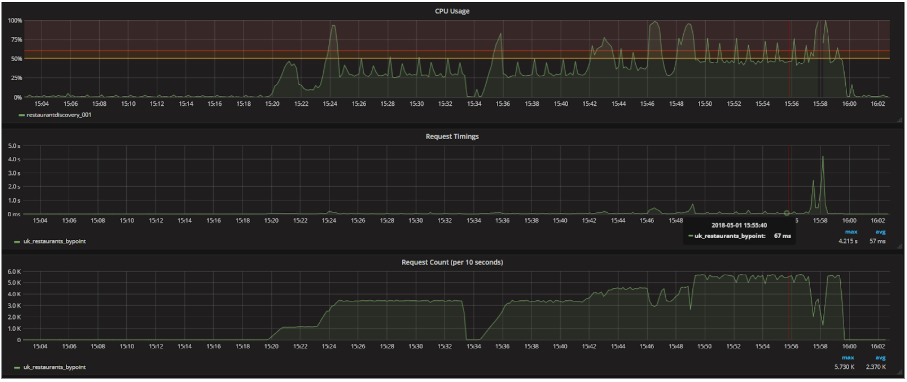
Once we had done this we pushed the system to destruction and found that we could go to 5x the load at the given configuration without having any significant performance degradation!
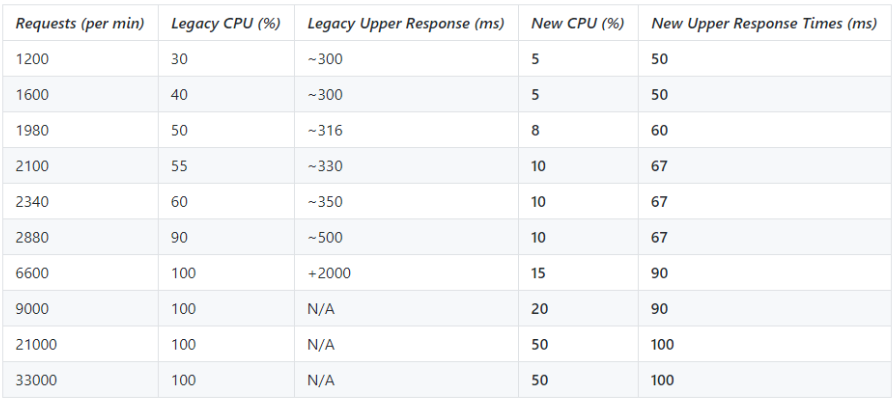
This meant that we could proceed and get buy in from the wider business to kick off a project of work to deliver this fully into production.
Dual Call and Circuit Break — Take 1
As part of the plan presented, we decided that the lowest risk approach was to implement a refactoring approach which would dual call the 2 systems at our orchestration layer and then compare the results from the calls. This was fairly straightforward to do as we leveraged the help of a library called Scientist.NET, a refactoring tool.
This tool provided a good framework for how we could have a control vs candidate comparisons made which would give us an indication of where we had any differences in our logic. This would also be living in the real world, in production, against live traffic. We could in real time see when and where we had any issues.
What we also implemented was circuit breaking of the calls to the new API, to shield it further from any potential failure due to slow response times. We implemented this using Polly, a circuit breaking library which allow for us to programmatically stop calling any failing services/dependencies.
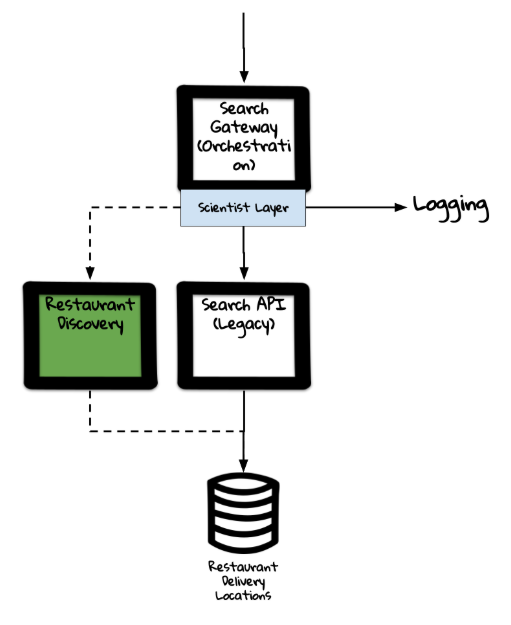
With these 2 tools in place we were able to record statistics and logs over time which gave us a picture of when and where discrepancies were occurring and how we should fix them.
However, we made a mistake. We attempted to start doing this for 100% of traffic. Because of a bug that we later found in our comparison logic, our orchestration service started using too much memory and CPU and crashed. Luckily with the monitoring and alerting we had in place this was caught and reverted.
The positive: We failed fast. The negative: We impacted consumers. We said that couldn’t happen!
Dual Call and Circuit Break — Take 2
With the fixes in place, we attempted to roll out these changes again, this time in a staggered approach. We released behind a feature toggle with 1%, 10%, 25%, 50%, 100% increments to traffic which was included in our comparison.
Compare and Switch
With 100% of traffic being compared, we were able to then look back through logs at our leisure for any discrepancies. We did find some; we had missed some fields or had rounding issues here and there. We put in fixes and managed to get this down to 0 discrepancies!
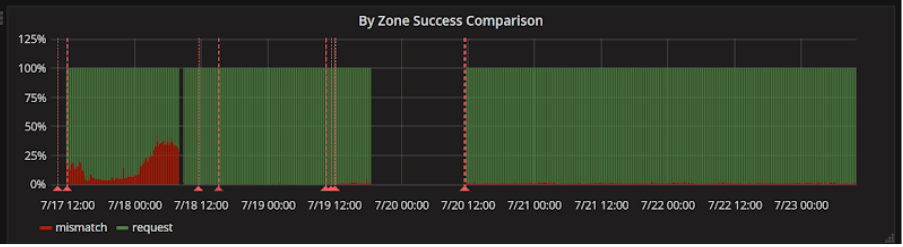
The next step was to switch the traffic we were sending. This would simply be switching the candidate and source data within our Scientist code. This would mean that we could continue doing comparisons but would prefer to return the results from our new API. Just for some extra safety, we included an additional feature toggle to allow for us to switch back if needed.
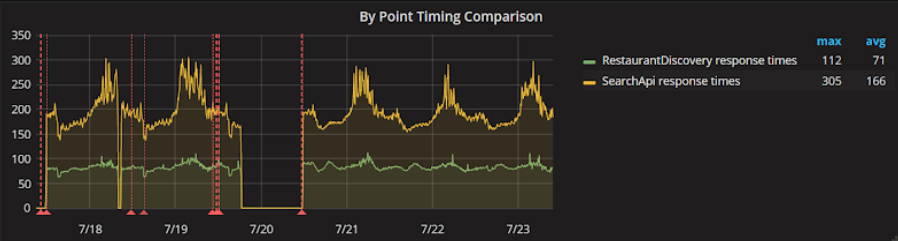
With this, we had successfully (with a few hiccups!) managed to get a new API ready for full release with a relatively low risk approach — All responses were still coming from the system, we had confidence that we had implemented everything correctly and we could still disable its use at any time if something happened. We let this run for a week in this configuration before we decided we had enough data to be 100% confident.
In fact, once we released the new code, we saw an immediate improvement in response times from our dependent APIs.
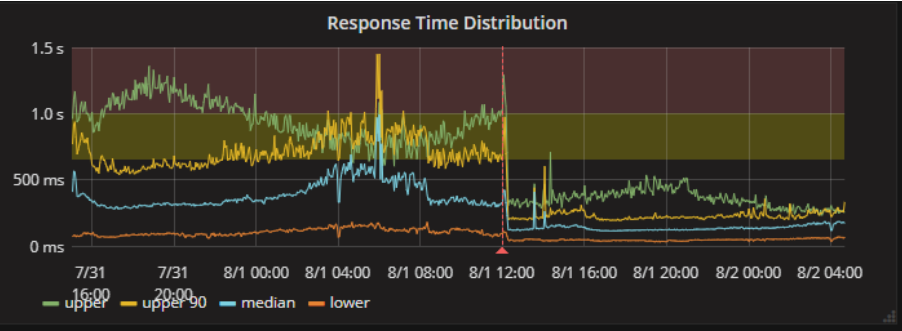
Deprecate!
We were able to remove the feature toggles, the comparison code, the code paths calling the old APIs within our domain and scale down the old services. This was definitely satisfying to do, but it did take longer than anticipated.
Due to the nature of the legacy component, its deprecation had a long sting in the tail caused by other domains still using it. We were able to fully derisk our domain, however. This was in fact highlighted by an outage which was caused by the legacy component and the search domain was unaffected … to the surprise of management and operations, but not to us!
Final Thoughts
It is never easy to make large scale changes to a code base without disruption. This in itself can mean changes are not made due to the risks of disruption. By taking advantage of techniques such as dual calling, circuit breaking and feature toggling, you can reduce the risk significantly and make these types of changes in a safe fashion